
Software – building the foundation for Big Data Success

Thibaut Loilier is in charge of Market Research for GFT. As author for CODE_n he shares his knowledge of the start-up business his time in Silicon Valley.
Thibaut Loilier is in charge of Market Research for GFT, member of the innovation team and author of GFT public whitepapers (Open Innovation, Mobile Banking, Mobile Payment and IT Trends). Before joining GFT, he worked as Business Strategy Analyst for BNP Paribas in San Francisco with responsibility for strategic analysis and relationship with Silicon Valley’s technology and innovation ecosystems (start-ups, academics, clusters…). He brings his experience within and knowledge of the start-up industry & ecosystem to the CODE_n initiative.
In the first post of this series “Building the Foundations for Big Data Success”, we introduced several companies that are addressing different software challenges posed by the world of big data, companies like Cloudera, Domo, Data Gravity, and Sqrrll. These companies are, of course, just the tip of the iceberg – the number of start-ups entering the big data marketplace is growing every day.
If you’ve been researching big data players, you may have come across the Big Data Startups Blog. On December 9th, the site published an eye-opening infographic showing the massive scale of investments being made by the new dedicated big-data VC funds in big data start-ups and the huge sums of money changing hands in big data IPOs and acquisitions.
Spending on big data has risen exponentially, from $4.9B over the period 2008-2012 to more than $3.6B in 2013 alone. The majority of this revenue was generated by just ten start-ups:

Palantir, MongoDB and Mu Sigma generate in total 60 % revenue out of the overall big data spendings
These companies are addressing several business needs:
- Analytics solutions
- Data Science as a Service
- Hadoop-based software, services and training
- Document-oriented databases
- Cassandra-based solutions
- Cloud-based approaches
- NoSQL databases
The types of businesses investing in big data solutions are equally diverse, ranging from healthcare and insurance to retail and marketing to governments and utilities.
The wide-ranging interest in software solutions to help businesses maximise the potential benefits from big data goes a long way towards explaining why the field is growing so quickly in size and value. Even though these solutions represent different approaches and different scopes, they share a common aim of managing an infrastructure that can process large amounts of unstructured data. Additionally, these solutions are applying customized algorithms to uncover valuable insights hidden within these vast data stores.
Palantir, for example, focuses on cyber fraud, financial trading, counterterrorism, disease tracking, and other crisis-related issues, but their products can be applied to anything from home lending patterns to healthcare delivery systems. Then there’s Mu Sigma, which brings a combination of business, math, and technology expertise to bear on big data analytics. MongoDB is a NoSQL database with a dynamic document structure designed to simplify integration with third-party data applications, while Cloudera is an open-source Apache Hadoop distribution.
Just as valuable as the breadth of capabilities across these developers is the provision of a clean visual representation of the data insights, enabling organisations to easily review, interpret, and act on the results..
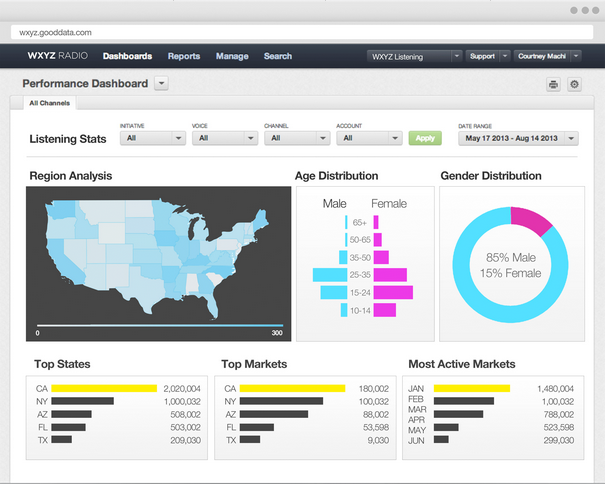
It is clear that 2013 has been big data’s most successful year to date, and that we can expect this level of expansion to continue for the next several years. The move to Big Data has only just begun, and the pace of big data start-ups, investments, acquisitions, and mergers – thanks in part to CODE_n and similar initiatives – seems set to keep this market a hot space for some time.
But the biggest beneficiaries of all this activity will be the organisations looking to benefit from big data, with more and more options available to help them gain truly valuable insights from their data.




Write a comment