
Infrastructure – Building the Foundations for Big Data Success

Dr. Ignasi Barri is an expert in innovation management in the technology surrounding and shares his experience on the CODE_n blog
Dr. Ignasi Barri is member of Applied Technologies in GFT Company. His fascination for technology and business helps him in his main goal: empowering innovation in the whole company. Innovation and business experience are combining perfectly to help him in being an author for the CODE_n organization.
As we noted in our first Big Data post, careful planning is key for the successful creation of a big data-ready infrastructure. Big data requires more than a change in mindset – it requires a change in the technologies used to deal with the different types of data in play and the way they need to be handled to maximize the benefits.
Organizations must analyze what data they have and how they want to use that data in order to match back-end infrastructure needs to application requirements; simply looking at the data and the infrastructure as if they exist in separate silos will not provide an appropriate solution.
Five key elements must be addressed to develop an appropriate strategy that takes all aspects of big data use and optimization into account:
- Cluster Design should be based on application requirements, including workload, volume, and energy consumption. Security must be considered from the outset, particularly where public cloud storage is an option; for example, when third-party data is involved, the output may take the form of new datasets that are more sensitive than the input data. Infochimps’ cloud services suite is one of the most promising platforms in this space, and is worth closer examination.
- Hardware Architecture can get very expensive, given the amount of data required to be stored, so the ability to use commodity rather than custom hardware (as recommended by the big players) is to be welcomed. Decide which elements are important for you – higher RAM plus moderate HDD performance, higher RAM plus higher CPU speed, high-performance GPUs to boost performance by up to 200 times are all options currently available from name-brand hardware vendors.
- Network Architecture must also be carefully considered, as a standard network setup may result in over-estimated network deployment and negatively impact the MapReduce algorithm (more in a future post on this). Customized solutions are appearing that take into account inputs from cluster design and application requirements.
- Storage Architecture is where planned big data usage comes into play. Do you need to manage active or archive data (or both)? How quickly do you need to access that data? As you can see in the diagram below, your choice can have a big impact on your budget.
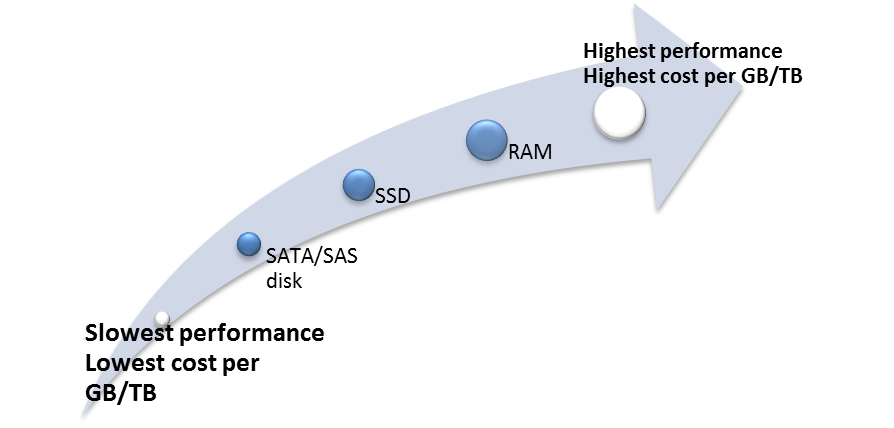
Well-received smart data storage solutions are available at Precog, designed to enable arbitrarily complex analytics, Couchbase, a flexible and scalable open-source community solution, and DataStax,built on the tried and tested Apache Cassandra platform. Go for DAS (Direct-Access Storage) if you can – it’s more suitable for big data than NAS or SAN.
- Information Security Architecture is an essential element; don’t rely on network and perimeter security to support big data infrastructure. Look instead at platforms like Sqrrl Enterprise, which offers cell-level access controls – the most granular protection possible. Such an approach lets organizations bring all their data together in a single platform (i.e., multitenancy) while complying with security, privacy, and regulatory requirements and applying different security levels to different data types.
That’s all for this time. Next up: software for big data success.




Write a comment